性能优化
# DB优化方案
# 优化思路
在代码开发过程中,我们都会遵循一些SQL开发规范去编写高质量SQL,来提高接口的Response Time(RT),对一些核心接口要求RT在100ms以内甚至更低。
由于业务前期数据量比较小,基本都能满足这个要求,但随着业务量的增长,数据量也随之增加,对应接口的SQL耗时也在变长,直接影响了用户的体验,这时候就需要对SQL进行优化。
优化点主要包括SQL规范性检查,表结构索引检查,SQL优化案例分析,下面从这三方面结合实际案例去如何优化SQL
# SQL规范性检查
select检查
- UDF用户自定义函数
UDF是mysql的一个拓展接口,UDF(Userdefined function)可翻译为用户自定义函数,这个是用来拓展Mysql的技术手段 SQL语句的select后面使用了自定义函数UDF,SQL返回多少行,那么UDF函数就会被调用多少次,这是非常影响性能的。


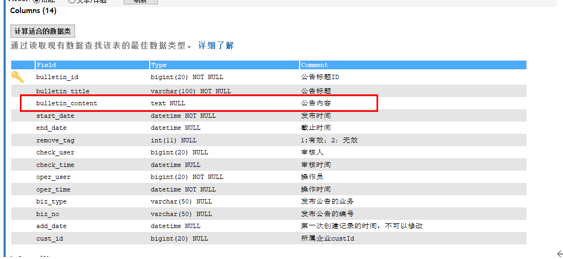
text类型检查
如果select出现text类型的字段,就会消耗大量的网络和IO带宽,由于返回的内容过大超过max_allowed_packet设置会导致程序报错,需要评估谨慎使用,且text类型的字段作为描述字段存储,获取列表数据时,若列表不展示,必须要过滤掉该查询字段。

group_concat函数
gorup_concat是一个字符串聚合函数,会影响SQL的响应时间,如果返回的值过大超过了max_allowed_packet设置会导致程序报错

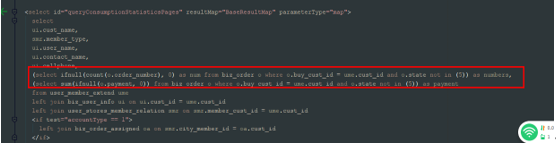
内联子查询
在select后面有子查询的情况称为内联子查询,SQL返回多少行,子查询就需要执行过多少次,严重影响SQL性能
from检查
由于MySQL的基于成本的优化器CBO对子查询的处理能力比较弱,不建议使用子查询,可以改写成Inner Join
where 检查
- 索引列被运算
当一个字段被索引,同时出现where条件后面,是不能进行任何运算,会导致索引失效

- 类型转换
对于Int类型的字段,传varchar类型的值是可以走索引,MySQL内部自动做了隐式类型转换;相反对于varchar类型字段传入Int值是无法走索引的,应该做到对应的字段类型传对应的值总是对的。还有一种情况 如果做连表的关联如果关联字段类型不同那么也是不走索引的

- 字符集
从MySQL 5.6开始建议所有对象字符集应该使用用utf8mb4,包括MySQL实例字符集,数据库字符集,表字符集,列字符集。避免在关联查询Join时字段字符集不匹配导致索引失效,同时目前只有utf8mb4支持emoji表情存储
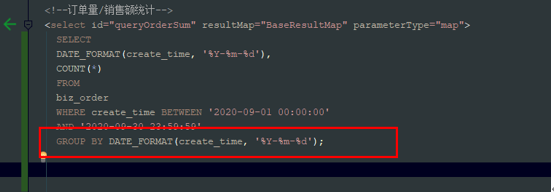
group by 检查
函数运算:分组查询中如果用到分组函数,则在分组时如果用到了mysql的函数运算,则会导致被分组的字段的索引无效
order by 检查
1,前缀索引 order by后面的列有索引,索引可以消除排序带来的CPU开销,如果是前缀索引,是不能消除排序带来的开销 2,字段顺序 排序字段顺序,asc/desc升降要跟索引保持一致,充分利用索引的有序性来消除排序带来的CPU开销limit 检查
对于limit m, n分页查询,越往后面翻页即m越大的情况下SQL的耗时会越来越长,对于这种应该先取出主键id,然后通过主键id跟原表进行Join关联查询
# 表结构检查
说明
在数据库设计建模阶段,对表名及字段名设置要合理,不能使用MySQL的关键字,如desc, order, status, group等。同时建议设置lower_case_table_names = 1表名不区分大小写
NOT NULL属性
根据业务含义,尽量将字段都添加上NOT NULL DEFAULT VALUE属性,如果列值存储了大量的NULL,会影响索引的稳定性
DEFAULT属性
在创建表的时候,建议每个字段尽量都有默认值,禁止DEFAULT NULL,而是对字段类型填充响应的默认值
COMMENT属性
字段的备注要能明确该字段的作用,尤其是某些表示状态的字段,要显式的写出该字段所有可能的状态数值以及该数值的含义
TEXT类型
不建议使用Text数据类型,一方面由于传输大量的数据包可能会超过max_allowed_packet设置导致程序报错,另一方面表上的DML操作都会变的很慢,建议采用es或者对象存储OSS来存储和检索
# 索引检查
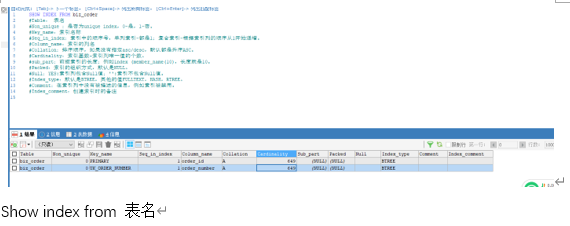
索引属性
索引基数指的是被索引的列唯一值的个数,唯一值越多接近表的count(*)说明索引的选择率越高,通过索引扫描的行数就越少,性能就越高
复合索引
MySQL遵循的是索引最左匹配原则,对于复合索引,从左到右依次扫描索引列,但是mysql会有自动排序机制,会对打乱的顺序进行自动排序。除非复合索引查询语句中没有复合索引的第一个字段
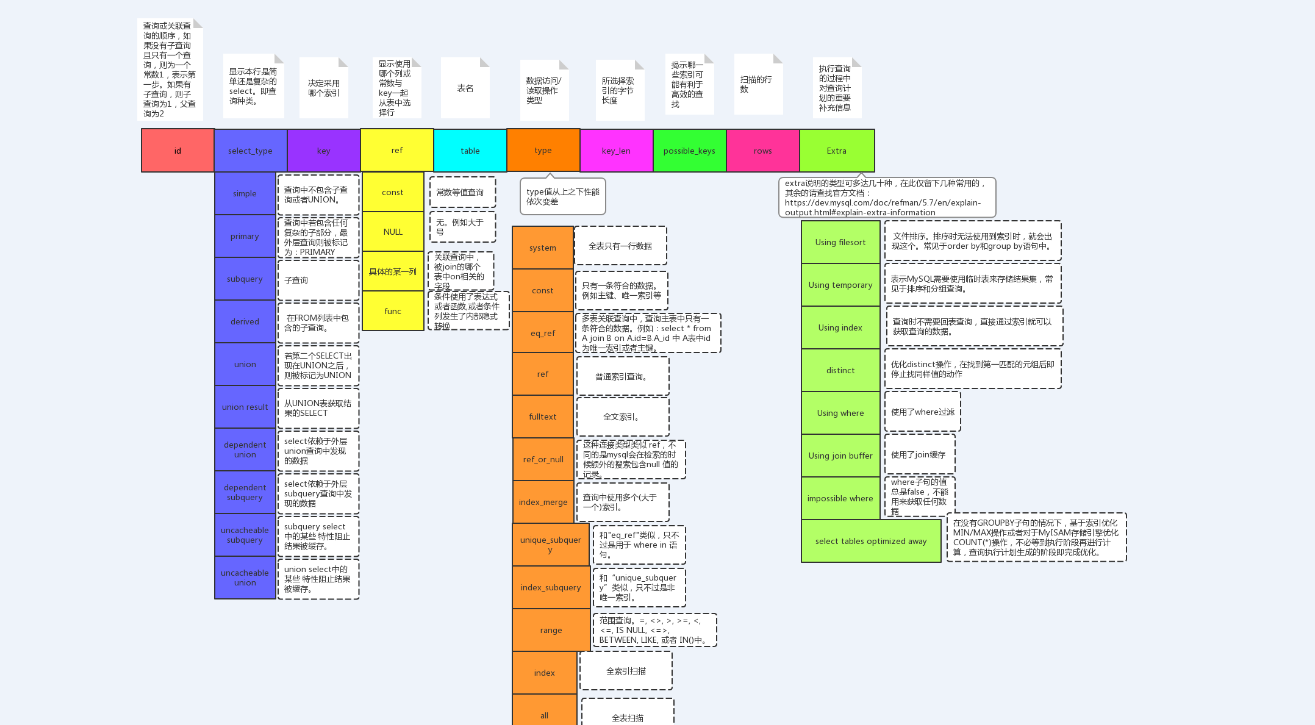
执行计划
执行计划,简单的来说,是SQL在数据库中执行时的表现情况,通常用于SQL性能分析,优化等场景。在MySQL中使用 explain 关键字来查看,最终目的需要优化执行sql里面的type等级以及检索行数row,type等级越高,执行效率越高
# 业务优化方案
# 优化思路
在项目上线之后,随着时间移动,系统所存储的数据日益增加,可能会导致接口响应速度越来越来,一方面可以针对DB做优化方案,另一方面针对业务层面的优化也是很有必要。业务层面的优化一方面是针对热点数据做缓存处理,另一方面在开发过程中代码规范也是影响系统性能的因素之一。以下会从缓存层面以及代码规范层面做优化阐述
# 业务缓存
缓存作用
1,加快数据访问速度,加快响应时间 2,减轻后端应用和数据存储的负载压力,减少DB交互次数缓存特征
1,衡量缓存有效性的重要指标。命中率越高,表明缓存的使用率越高,命中率= 命中数/请求次数 2,最大元素,一旦缓存中元素数量超过这个值(或者缓存数据空间超过其最大支持空间),将会触发淘汰策略 3,淘汰策略,分三种类型。FIFO(First In First Out) 先进先出,淘汰最早数据,判断存储时间,离目前最远的数据优先淘汰。LRU (Least Recently Used)剔除最近最少使用,判断最近使用时间,离目前最远的数据优先淘汰。LFU (Least Frequently Used)剔除最近使用频率最低的数据,在一段时间内,数据被使用次数最少的,优先淘汰缓存使用
1,什么数据可以载入缓存或者使用缓存?
通常我们把热点数据载入缓存,用来加快访问速度。热点数据我们可以通过以下方式来判断。所谓热点,一般是遵循二八定律,即百分之八十的访问集中在百分之二十的数据上。以及读写比例大概在2:1 甚至大于。举例:系统的全局网站参数,数据字典,地区信息,以及商品信息 都遵循此规律。对于一些频繁操作的业务数据,建议不要放在缓存中以免造成脏读
2,缓存更新带来的数据不一致与脏读?
缓存更新的常见策略有:
1、先更新数据库再更新缓存;
2、先更新数据库再删除缓存;
3、先删除缓存再更新数据库;
4、定时清理缓存;
5、有请求访问数据时,判断缓存是否过期,过期从数据库中刷新缓存。
在这几种方案中,如果修改缓存与数据库不在同一个事物中,就带来了数据不一致和脏读的问题。
对应方案1:先删除缓存再更新数据库,并且在同一个事物中。
对应方案2:缓存自动失效后,另外的异步线程进行缓存更新。
对应方案3:缓存更新在并发、分布式要考虑锁,redis天生就是单线程,比较有优势。
3,缓存预热
缓存预热是指在用户可访问服务之前,将热点数据加载到缓存的操作,这样可以有效避免上线后瞬时大流量造成系统不可用
处理方案:开发个缓存刷新功能,手工刷新或者提前统计热点数据,事先批量加载到如redis这样缓存工具
4,缓存工具及特点
memcache本身不支持分布式,是通过客户端的路由处理来达到分布式解决方案 的目的。特点如下:
memcache使用预分配内存池的方式管理内存;
所有数据存储在物理内存里;
非阻塞IO复用模型,纯KV存取操作;
多线程,效率高,会遇到锁等上下文切换问题;
只支持简单KV数据类型;
数据不支持持久化
Redis是当前主流的高性能内存数据库,多用于存储缓存数据,并能实现轻量级的 MQ功能。特点如下:
临时申请空间,可能导致碎片;
有VM机制,能存储更多数据,超过内存空间后会导致swap,降低效率;
非阻塞IO复用模型,支持额外CPU计算:排序、聚合,会影响IO性能;
单线程,无锁,无上下文切换,单实例无法利用多核性能;
支持多种数据类型:string / hash / list / set / sorted set;
数据支持持久化:AOF(语句增量)/RDB(fork全量);
天然支持高可用分布式方案sentinel +;
cluster(故障自动转移+集群)
# 代码规范
- 集合初始化尽量指定大小
- 字符串拼接使用 StringBuilder
- 循环查询数据库
# 中间件
# ElasticSearch
ElasticSearch就是一款基于Lucene框架的分布式搜索引擎,并且也是一款为数不多的基于JSON进行索引的搜索引擎。ElasticSearch特别适合在云计算平台上使用。详情参加下文ES语法介绍及业务集成方式
# Lucene
毫无疑问,Lucene是目前最受欢迎的Java全文搜索框架,准确地说,它是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene为开发人员提供了相当完整的工具包,可以非常方便地实现强大的全文检索功能。下面有几款搜索引擎框架也是基于Lucene实现的。
# Solr
Solr也是基于Java实现的,并且是基于Lucene实现的,Solr的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,高亮显示搜索结果。值得注意的是,Solr还提供一款很棒的Web界面来管理索引的数据
# feign远程调用注意事项
有存在传很大数据量时传参不要用【GET】必须使用【POST JSON】
对于
GET请求,数据量不超过2KB-4KB。否则使用POST JSON。对于
POST请求发送JSON数据,数据量不超过10MB。否则就进行分批处理或其他方案。其他方案:
@Autowired
private OrderFeign qrderFeign;
// 1、远程调用 orderFeign
public void listAll(){
ParamsDTO paramsDTO = new ParamsDTO();
// 获取数据量大的放入OSS 中
List<OrderDTO> datas = goodsService.list();
// 塞入OSS 返回唯一ID
String objectId = OssDataUtils.putObject(datas);
// 塞入唯一ID
paramsDTO.setObjectId(objectId);
// 远程调用feign
qrderFeign.queryAll(paramsDTO)
}
// 2、feign 接收方法
public void queryAll(ParamsDTO paramsDTO){
// 接收oss里的数据
List<OrderDTO> datas = OssDataUtils.getObject(paramsDTO.getObjectId(),OrderDTO.class)
// TODO datas 数据获取业务逻辑处理
}
如果有些业务需要关联查询数据量很大,但是服务与服务之间数据库是分开的情况下要求
这种情况要求2个服务的数据库不要分开,直接合并再一起,通过sql关联查询方式进行操作。