JDK1.8特性
# 引言
# 编写目的
本文读者对象是:参与“同徽supsce系统”的设计、开发技术人员,针对平时检查代码时,发现的一些问题,做出以下的建议。
# java8
# 新特性
Java8 新增了非常多的特性,我们主要讨论以下几个:
- Stream API −新添加的Stream API(java.util.stream)把真正的函数式编程风格引入到Java中。
- Lambda 表达式 − Lambda 允许把函数作为一个方法的参数(函数作为参数传递到方法中)
- 方法引用 − 方法引用提供了非常有用的语法,可以直接引用已有Java类或对象(实例)的方法或构造器。与lambda联合使用,方法引用可以使语言的构造更紧凑简洁,减少冗余代码。
- 函数式接口 − 函数式接口在java指定的是:有且仅有一个抽象方法的接口就称为函数式接口。
# 开发规范
# OOP规约
① 所有的覆写方法,必须加@Override 注解。
说明:getObject()与 get0bject()的问题。一个是字母的 O,一个是数字的 0,加@Override 可以准确判 断是否覆盖成功。另外,如果在抽象类中对方法签名进行修改,其实现类会马上编译报错。
② 相同参数类型,相同业务含义,才可以使用 Java 的可变参数,避免使用 Object。
说明:可变参数必须放置在参数列表的最后。(提倡同学们尽量不用可变参数编程)
正例:public List listUsers(String type, Long... ids) {...}
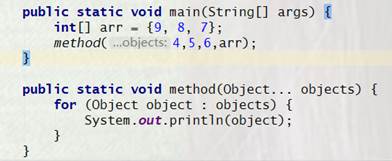
编译结果:

③ Object的 equals方法容易抛空指针异常,应使用常量或确定有值的对象来调用equals。
正例:"test".equals(object);
反例:object.equals("test")。
# 集合处理
①不要在 foreach 循环里进行元素的 remove 操作。remove元素请使用 Iterator 方式,如果并发操作,需要对 Iterator 对象加锁。
正例:

反例:

② 循环处理List对象中数据不允许在循环体内查询数据库。
③ArrayList的subList结果不可强转成ArrayList,否则会抛出 ClassCastException异常:
说明:subList 返回的是 ArrayList 的内部类 subList,并不是 ArrayList ,而是ArrayList 的一个视图,对于 subList 子列表的所有操作最终会反映到原列表上。
例子:

此处可以有另一种方式,对于Java8使用stream的skip和limit来跳过流中的元素,以及限制流中元素的个数,同样可以达到 subList 切片的目的。

④返回空数组和空集合而不是 null
说明:返回 null,需要调用方强制检测null,否则就会抛出空指针异常。返回空数组或空集合,有效地避免 了调用方因为未检测 null 而抛出空指针异常,还可以删除调用方检测 null 的语句使代码更简洁。
正例:

反例:

# 其他
① 使用String.valueOf(value)代替""+value
当要把其它对象或类型转化为字符串时,使用String.valueOf(value) 比""+value 的效率更高。


② 禁止使用构造方法 BigDecimal(double)
BigDecimal(double) 存在精度损失风险,在精确计算或值比较的场景中可能会导致业务逻辑异常。
正例:


反例:


# Stream
stream流是JDK8 新增的成员,允许以声明性方式处理数据集合,可以把 Stream 流看作是遍历数据集合的一个高级迭代器。
使用流的好处: 代码以声明性方式书写:说明想要完成什么,而不是说明如何完成一个操作 可以把几个基础操作连接起来,来表达复杂的数据处理的流水线,同时保持代码清晰可读。
# 什么是Steam?
Stream(流)是一个来自数据源的元素队列并支持聚合操作
- 元素是特定类型的对象,形成一个队列。 Java中的Stream并不会存储元素,而是按需计算。
- 数据源 流的来源。 可以是集合,数组,I/O channel, 产生器generator 等。
- 聚合操作 类似SQL语句一样的操作, 比如filter, map, reduce, find, match, sorted等。
和以前的Collection操作不同, Stream操作还有两个基础的特征:
- Pipelining: 中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(fluent style)。 这样做可以对操作进行优化, 比如延迟执行(laziness)和短路( short-circuiting)。
- 内部迭代: 以前对集合遍历都是通过Iterator或者For-Each的方式, 显式的在集合外部进行迭代, 这叫做外部迭代。 Stream提供了内部迭代的方式, 通过访问者模式(Visitor)实现。
# 循环遍历的弊端

Java 8的Lambda让我们可以更加专注于做什么(What),而不是怎么做(How),这点此前已经结合内部类进行了对比说明。现在,我们仔细体会一下上例代码,可以发现:
- for循环的语法就是“怎么做"
- for循环的循环体才是“做什么”
为什么使用循环?因为要进行遍历。但循环是遍历的唯一方式吗?遍历是指每一个元素逐一进行处理,而并不是从第一个到最后一个顺次处理的循环。前者是目的,后者是方式。
试想一下,如果希望对集合中的元素进行筛选过滤:
- 将集合A根据条件一过滤为子集B;
- 然后再根据条件二过滤为子集C。
那怎么办?在Java 8之前的做法可能为:

下面我们来看看Stream的更优写法:

# filter操作
源码:Stream<T> filter(Predicate<? super T> predicate);
一个单纯的过滤操作直接返回传入类型。
例子:

打印结果:

# map操作
源码:<R> Stream<R> map(Function<? super T, ? extends R> mapper);
这个方法传入一个Function的函数式接口,这个接口,接收一个泛型T,返回泛型R,map函数的定义,返回的流,表示的泛型是R对象,这个表示,调用这个函数后,可以改变返回的类型。后面,我们会看到,把map操作后,改变的对象类型,返回各种类型的集合,或者对数字类型的,返回求和,最大,最小等的操作。
例子:

打印结果:

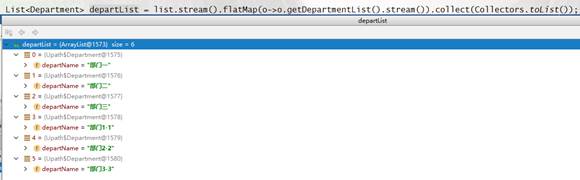
# flatMap操作
源码:<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);
这个接口,跟map一样,接收一个Fucntion的函数式接口,不同的是,Function接收的泛型参数,第二个参数是一个Stream流;方法,返回的也是泛型R,具体的作用是把两个流,变成一个流返回。
例子:


# limit/skip操作
limit返回Stream的前面n个元素;skip则是扔掉前n个元素。
例子:

运行结果:

# distinct操作
distinct()是Java 8中Stream提供的方法,返回的是由该流中不同元素组成的流。
源码:Stream<T> distinct();
例子:

运行结果:

# peek操作
源码:Stream<T> peek(Consumer<? super T> action);
peek 操作接收的是一个Consumer<T>函数。顾名思义 peek 操作会按照 Consumer<T>函数提供的逻辑去消费流中的每一个元素,同时有可能改变元素内部的一些属性。
例子:

执行结果:

# peek vs map
peek操作一般用于不想改变流中元素本身的类型或者只想操作元素的内部状态时;而 map 则用于改变流中元素本身类型,即从元素中派生出另一种类型的操作。这是他们之间的最大区别。 那么 peek 实际中我们会用于哪些场景呢?比如对 Stream<T> 中的 T 的某些属性进行批处理的时候用 peek 操作就比较合适。 如果我们要从 Stream<T> 中获取 T 的某个属性的集合时用 map 也就最好不过了。
# Stream将List转为Map

# Stream常见用法
① 分组(以OrdeId分组)
Map<Long,List<Order>> newOrderMap=orderList.stream()
.collect(Collectors.groupingBy(Order::getOrderId));
遍历:
for (Map.Entry< Long, List<Order>> item : newOrderMap.entrySet()) {
statesNum.put(item.getKey(), item.getValue().size());
}
② 分组(多条件分组)
Map<String, Map<Long, List<OrderItem>>> collect = orderList.stream().collect(Collectors.groupingBy(Order::getOrderId, Collectors.groupingBy(Order::getProductNum)));
③ 集合 (根据某个字段转成集合:OrdeId)
List<Long> orderIdList = orderList.stream().map(Order::getOrderId)
.collect(Collectors.toList());
④排序 (根据某个字段排序:OrdeId)
List<Order> newListAsc =orderList.stream().sorted(Comparator.comparing(Order::getOrderId)).collect(Collectors.toList());
List<Order> newListDesc =orderList.stream().sorted(Comparator.comparing(Order::getOrderId).reversed()).collect(Collectors.toList());
⑤ 组合排序:比如先按照积分倒序,再按照添加时间升序
List<IntegralAccountDTO> finallList = modelList.stream()
.sorted(Comparator.comparing(IntegralAccountDTO::getAvailableIntegral,Comparator.reverseOrder())
.thenComparing(IntegralAccountDTO::getAddTime)).collect(Collectors.toList());
⑥ 取最大值:
IntegralAccountDTO dto = finallList.stream().max(Comparator.comparing(IntegralAccountDTO::getAvailableIntegral)).get();
⑦ 取最小值:
IntegralAccountDTO dto = finallList.stream().min(Comparator.comparing(IntegralAccountDTO::getAvailableIntegral)).get();
⑧ 求和:
Double discountsFee = tempItems.stream().mapToDouble(OrderItem::getDiscountsFee).sum();
⑨对集合的结果进行去重
List<User> list = userList.stream()
.collect(Collectors.collectingAndThen(Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(User::getUserId))), ArrayList::new));
# Lambda表达式
# 概述
Lambda 表达式,也可称为闭包,它是推动 Java 8 发布的最重要新特性。
Lambda 允许把函数作为一个方法的参数(函数作为参数传递进方法中)。
使用 Lambda 表达式可以使代码变的更加简洁紧凑。
# 语法
(parameters) -> expression
或 (parameters) ->{ statements; }
# 特征
- 可选类型声明:不需要声明参数类型,编译器可以统一识别参数值。
- 可选的参数圆括号:一个参数无需定义圆括号,但多个参数需要定义圆括号。
- 可选的大括号:如果主体包含了一个语句,就不需要使用大括号。
- 可选的返回关键字:如果主体只有一个表达式返回值则编译器会自动返回值,大括号需要指定明表达式返回了一个数值。
# 语法与实例
参数类型可省略:
(param1,param2, ..., paramN) -> { statment1; statment2; //............. return statmentM; }
一个参数时,圆括号可省略:
param1 -> { statment1; statment2; //............. return statmentM; }
只包含一条语句时,可以省略大括号、return和语句结尾的分号:
param1 -> statement
实例:
List<String> names = new ArrayList<>(); names.add("TaoBao"); names.add("ZhiFuBao");
不使用Lambda表达式写法: List<String> lowercaseNames = new ArrayList<>(); for (String name : names) { lowercaseNames.add(name.toLowerCase()); }
使用Lambda表达式写法:
List<String> lowercaseNames = names.stream().map(o -> o.toLowerCase()).collect(Collectors.toList());
# 方法引用
# 概述
前面介绍lambda表达式简化的时候,已经看过方法引用的身影了。方法引用可以在某些条件成立的情况下,更加简化lambda表达式的声明。
# 语法与实例
- objectName::instanceMethod
- ClassName::staticMethod
- ClassName::instanceMethod
1、前两种方式类似,等同于把lambda表达式的参数直接当成instanceMethod或staticMethod的参数来调用。
比如:
System.out::println等同于x->System.out.println(x);
Math::max等同于(x, y)->Math.max(x,y)。
2、最后一种方式,等同于把lambda表达式的第一个参数当成instanceMethod的目标对象,其他剩余参数当成该方法的参数。
比如:String::toLowerCase等同于x->x.toLowerCase()
还有个构造器引用,它的语法是Class::new,或者更一般的Class<T>::new
例如:BigDecimal::new等同于x->new BigDecimal(x)
# 函数式接口
# 概述
函数式接口,设用于函数式编程的,在java当中的函数式编程体现在Lambda,所以函数式接口就是用来服务Lambda表达式。
# 实例
JDK 1.8 新增加的函数接口java.util.function,它包含了很多类,用来支持 Java的 函数式编程,该包中的函数式接口有很多,下面以订单为例,告诉大家这样使用的优点。


Function<T,R>:接受一个输入参数,返回一个结果。
UnaryOperator<T>:接受一个参数为类型T,返回值类型也为T。
Consumer<T>:代表了接受一个输入参数并且无返回的操作。
- Function: 接收参数,并返回结果,主要方法 R apply(T t)
- Consumer: 接收参数,无返回结果, 主要方法为 void accept(T t)
- Supplier: 不接收参数,但返回结果,主要方法为 T get()
- Predicate: 接收参数,返回boolean值,主要方法为 boolean test(T t)
如何调用?看下图

这是个多商家下单的一个例子,参数c是这个调用者对自己内部业务的数据校验,dealfunc参数是数据处理的回调,参数e是订单处理完之后,自己内部业务需要做的一些事~~图中代码是做了清除redis操作,像多种订单来源走下单,可能存入的redis的key是不一样的,所以不能在公共处理订单方法体内去做这些事,这时候,每个来源删除自己的key,是不是很方便。 之前,订单中心会写各种各样的下单方法,就是因为有不同的处理,我们可以重载不一样的下单方法,有的业务不需要做校验,或者不需要下完单处理自己的业务,这样我们就可以通过不传某些参数,避免我们走那段代码。这样就可以做到各司其职,互不影响,也不用写多个入口。